In the previous blog in this series, I talked about how consumers expect a company to handle their data, particularly in the context of ‘Guest’ access. When will that data be removed permanently?
Who will have access to it before it does? How securely is the data stored?
Backlog privacy debt
‘Guest’ order data is just one example of ‘backlog privacy debt’ that is residing in most ERP systems. This is data for which there are clearly no legal grounds for still having, and typically has only not been removed because of the complexity of purging the ERP system of this data. It could also apply to CRM systems; but in most cases those were designed with an understanding that some data will be transient, and they include mechanisms for removing data when no longer required.
The founding principles of ERP systems, and certainly SAP ERP, were in fact opposite – full integration and traceability of all data at all times. I wrote about this when GDPR was first being introduced and the challenge it posed for the ‘Right to be Forgotten’. This means most companies running SAP are sitting on some form or other of data that they simply cannot justify still having in their systems.
Of course there are other examples of ‘Backlog Privacy Debt’ too, such as employees who have long since left the organisation. The looser the employee relationship, the shorter the period for which we should keep their data. Examples could be seasonal workers in retail systems who may or may not return next year, or contractors employed for a specific short-term project.
Another common example for industries where acquisitions and divestitures is common are Employees/Customers/Vendors who are part of a business that was long since sold off. Or even data in a system that was taken over as part of an acquisition, but was never part of the purchased business. Ten years ago, when acquisitions occurred there was very little concern for data privacy. Transferring the required systems and data for running the business was the sole aim of the technical project, and if a little extra data was included, who cared? Now, M&A (Mergers & Acquisitions) projects must take Data Privacy incredibly seriously, just as any other project should - ‘By default and by design’.
Removing data in SAP, Archiving (SAP ILM) or nothing
There are two big challenges with removing data from ERP systems and particularly SAP:
- The traceability of changes in the system
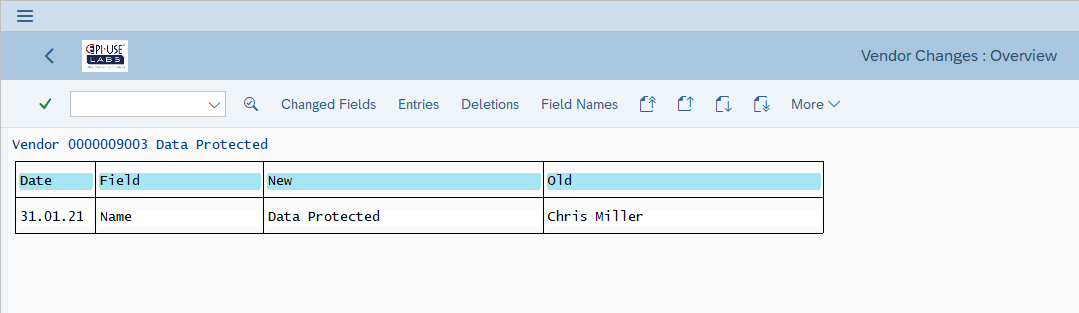
If the business users simply go and change the data through standard transactions, the system keeps records of the changes, and therefore the previous data too, for example Vendor/Customer/BP change documents: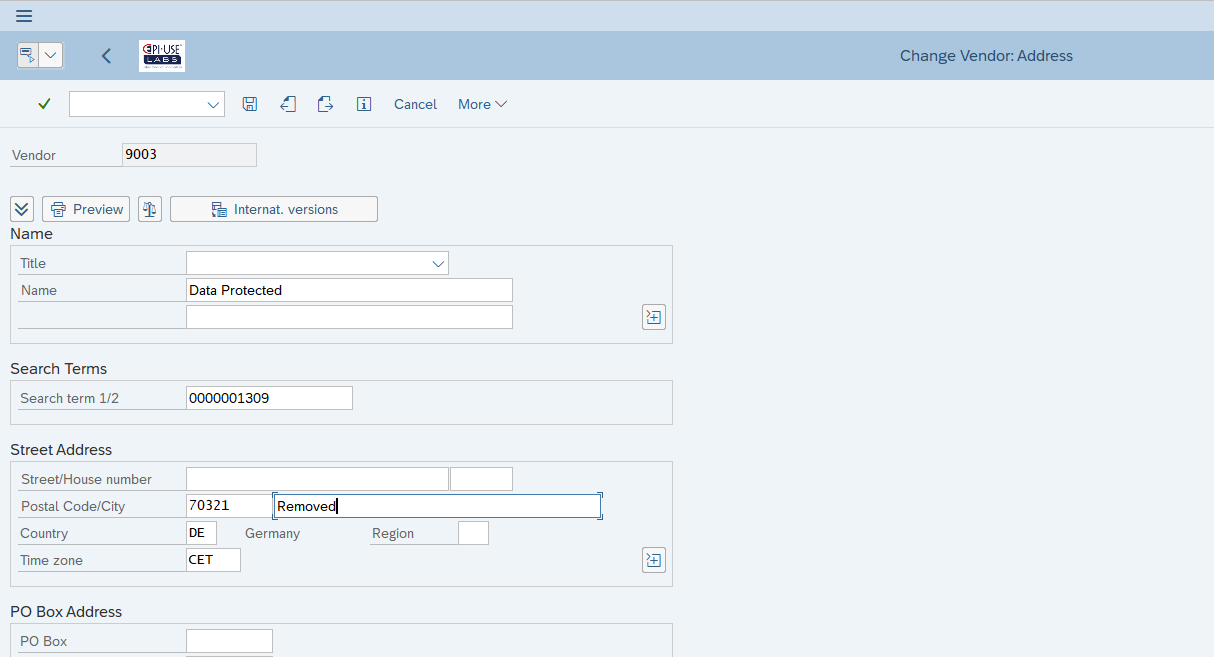
- The interconnectivity of ERP systems
If we instead go directly to the table level and delete records containing this personal data, there would then be inconsistencies in the system. For example, Sales Orders referencing a Customer master key that no longer exists.
The only standard way to remove data so that neither of these will be an issue is to mark the data for deletion and then archive it. This takes the data to a separate file on the operating system, typically from where the data can still be read from the SAP system, but never changed. The purpose of archiving was never to rid the system of historical personal data, but by removing the archive files, this can be achieved. The big problem with this, though, is that the archiving process requires that any transaction that references the master data be archived first. And to archive each transaction, you must first archive any subsequent transactions. So, for example, in order to archive Customer masters we must first archive Sales Orders but to archive the Sales Order the Delivery must first be archived...and all the way along to accounting documents. This process was not designed for the purpose of just removing sensitive or personal data, and it shows when applied to that challenge.
S/4HANA in the mix
Where would a SAP blog be without an S/4HANA mention? Well, in embarking on, or preparing for, an S/4HANA migration, both data cleansing and archiving are typically discussed. Don’t confuse this with handling backlog privacy debt. The data cleansing rarely deals with purging unrequired data, unless the project is a Greenfield one where this backlog debt can simply be left behind. Typically it is the CVI (Customer/Vendor Integration) process and de-duplicating master records, or correcting formatting mistakes.
Archiving is considered in Brownfield projects to shrink the potential size of the future system’s database, the majority of space savings being achieved by taking out large amounts of
transactional data rather than historical master data.
The alternative: Redaction
If there is no major space saving from fully purging our backlog privacy debt, and the process throws up many more difficult challenges, as well as potentially removing valuable non-sensitive data such as geographical spread of customers, gender reporting capability on historical employees, then surely there is a better way? The issue with letting the business simply change the data to remove the identifiable values was that the change itself is tracked. If we rather go directly to the table level and replace anything sensitive or identifying, then we can do so from the beginning of the data’s existence, not a change as of today.
But all the surrounding information which may still be useful for reporting can be kept. And any dependency from foreign key relationships in transactional data, or even references from related master data (e.g. Addresses, WBS data, Contact Persons) will still be intact.
Practical example 1: Vendor Master
Here we see the same Vendor we looked at previously but now programmatically we have redacted sensitive fields in LFA1, LFB1, ADRC. 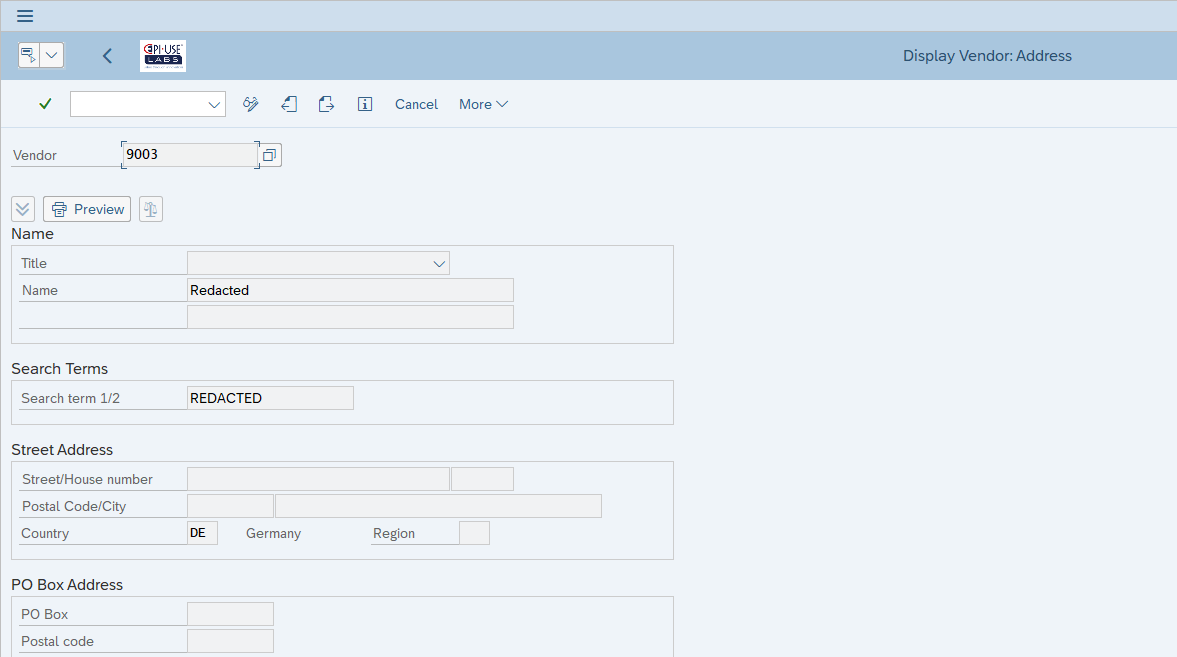

With all change documents removed (since original values can be there)
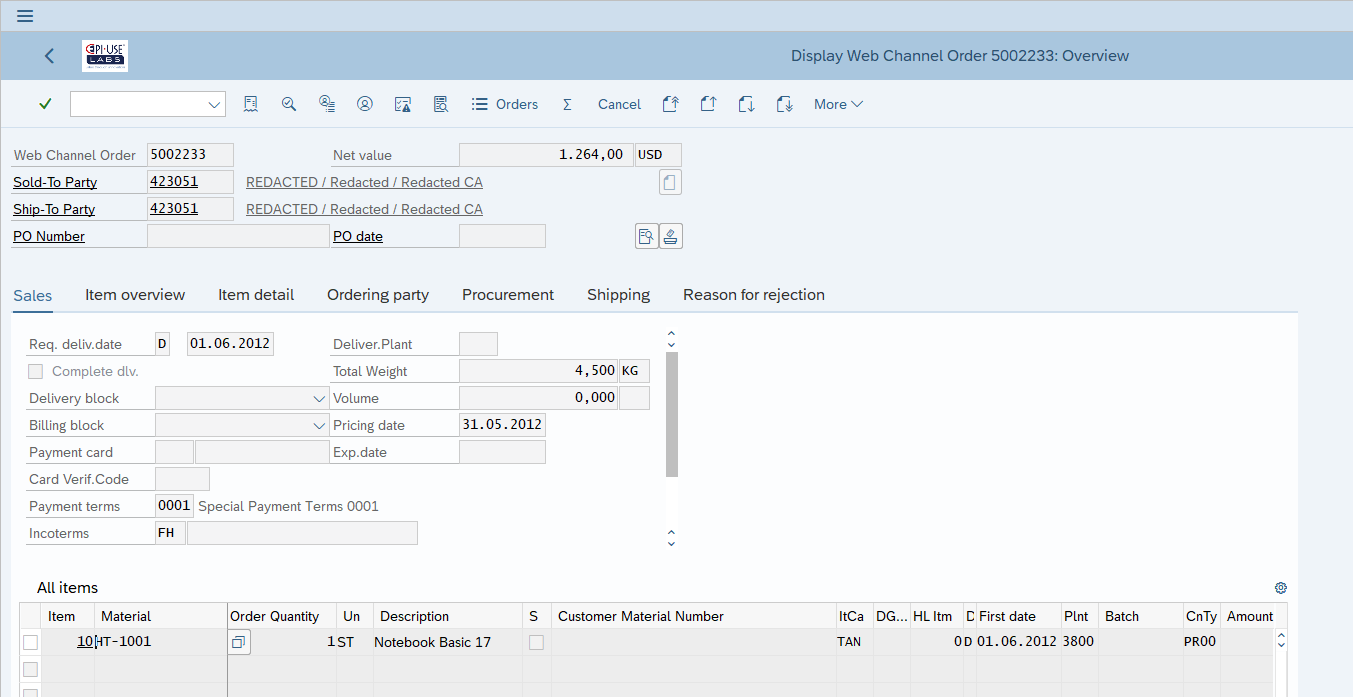
Practical example 2: Customer Master in Orders
In this example, the master data from KNA1, ADRC, etc. which is maintained via XD02 is visible in the Sales Order transaction (VA03) because of the link in table VPBA. We don’t need to make any changes to the order at all in this example. All the personal data is being pulled through. So changes – similar to what we made in the first example for Vendor, now made to the Customer master – also ensure orders for that customer are no longer showing personal data values.
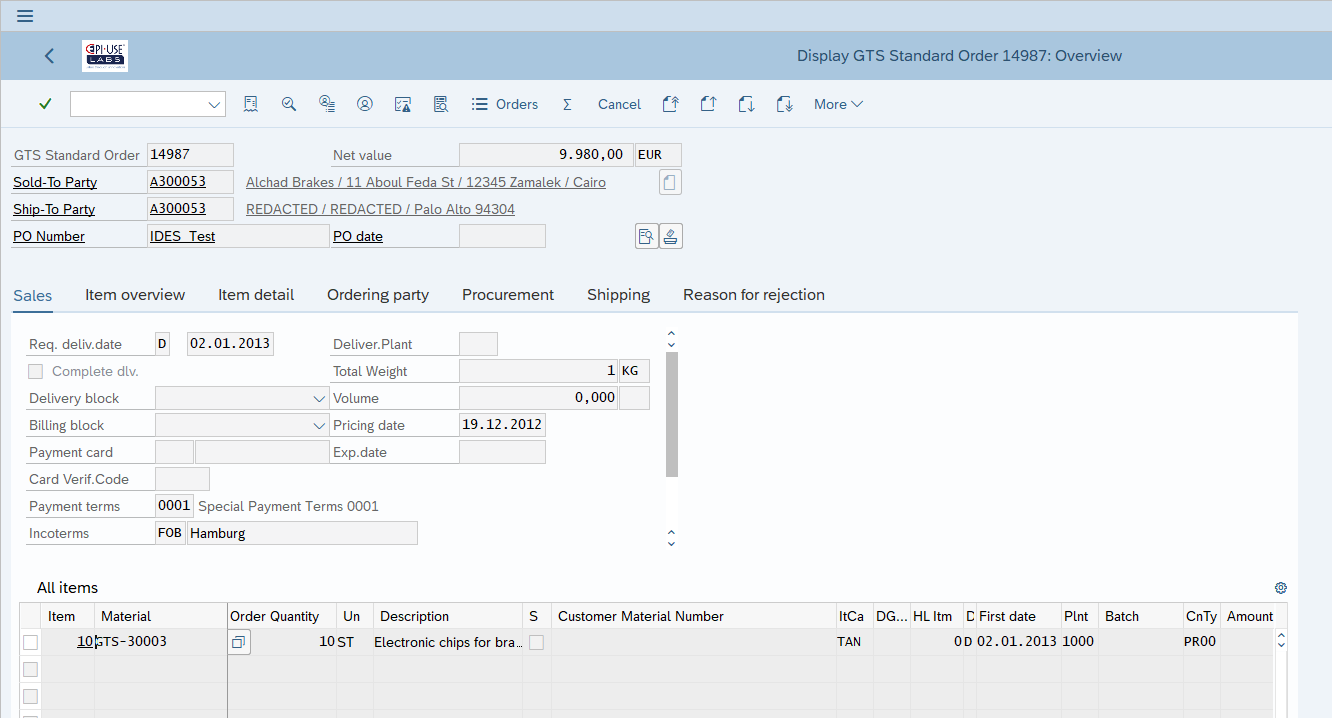
Practical example 3: Bespoke Addresses in Orders
In the previous blog, I focused on the topic of custom or bespoke addresses, either as part of a ‘Guest’ purchase process or where the inherited address from the master data record has been adapted for this particular order. Now we see a different address record linked to the order in VPBA and have instead redacted that data in ADRC programmatically.
That all sounds easy enough - where’s the catch?
The challenge with setting up your own redaction programs is the number of places the data can also reside. It’s not impossible to find them all, but it's something that also needs to be reviewed if business processes change, and when upgrading SAP in the future. Some examples are:- Change Documents in the CDHR table and CDPOS cluster
Although we don’t generate change documents in our redaction process there may still be some, and they may include real changes - e.g. a customer change of address. Both the old and new values are personal data for that consumer. - ADRC, ADR2, ADCP, ADRP, etc.
Depending on the customising of the system and the type of address data, different fields in different tables can store these personal data values. It’s essential to track them all down but only affect the intended addresses, and not accidentally pick up a customising address for example. - Cluster data
Transparent tables are typically easy to handle and even clusters like CDPOS where the key is outside the raw cluster data. But in some cases (like the HCM data I’ll cover in the next blog) the actual identifier is harder to spot - e.g. Employee number in the PCL2 cluster. But also where the personal data in the cluster is located can vary from system to system, and even record to record, based on the country of the employee for example, or other properties of the particular data record in scope.
EPI-USE Labs redaction technology
We have developed software that can be leveraged directly by organisations to carry out their own redactions, either reactively to individual requests, or as part of an automatic periodic application of a retention period. We also provide services and guidance to help manage the major initial clean up of backlog privacy debt. Reach out if you want assistance from the experts.
Minimal activity to satisfy historical data minimisation requirements for compliance.