In meinem letzten Blog habe ich über die Erwartungen der Verbraucher an Unternehmen im Umgang mit Ihren personenbezogenen Daten geschrieben. Dabei lag mein Fokus insbesondere auf den Daten, die während einer Bestellung als "Gast" im ERP-System hinterlegt werden. Wann werden diese Daten dauerhaft gelöscht? Wer hatte Zugriff? Und wie sicher sind die Daten gespeichert?
Backlog im Datenschutz
Bestelldaten von „Gästen“ sind nur ein Beispiel für Backlogs im Datenschutz, wie sie in den meisten ERP-Systemen vorkommen. Für das Speichern dieser Daten fehlt die rechtliche Grundlage, doch es ist schwierig und komplex die Daten aus den ERP-Systemen zu entfernen.
Anders als in CRM-Systemen, bei denen ein Mechanismus zum Entfernen von Daten vorgesehen ist, sind die grundlegenden Eigenschaften von ERP-Systemen das genaue Gegenteil: volle Integration und Rückverfolgbarkeit aller Daten zu jeder Zeit. Diese Eigenschaften stellen in Bezug zum „Recht auf Vergessenwerden“ eine große Herausforderung dar, denn viele SAP Kunden haben Daten in Ihren Systemen, deren Speicherung sie einfach nicht rechtfertigen können.
Neben Gast-Bestellungen gibt es noch unzählige weitere Beispiele, wie Mitarbeiter, die das Unternehmen schon längst verlassen haben, Saisonarbeiter, deren Wiedereinstellung im nächsten Jahr noch nicht sicher ist, oder Auftragnehmern, die nur für ein bestimmtes Projekt angestellt wurden. Je unverbindlicher das Arbeitsverhältnis, desto kürzer sollten die betroffen Daten gespeichert werden.
Auch Übernahmen und Veräußerungen sind ein weiteres Bespiel. Dabei sind Lieferanten, Kunden und Mitarbeiter Datensätze des veräußerten Unternehmens betroffen. Noch vor 10 Jahren wurde bei Übernahmen nicht sonderlich auf das Thema Datenschutz geachtet. Das einzige Ziel des technischen Projektes war die erfolgreiche Übertragung der Systeme und Daten. Heute ist Datenschutz in M&A (Mergers & Acquisitions) Projekten, wie auch in allen anderen Projekte, essenziell wichtig.
Datensätze in SAP: Löschen, Archivieren (SAP ILM) oder Nichts
Möchten Sie Daten aus dem SAP ERP-System entfernen, stehen Sie vor zwei großen Herausforderungen:
- Die Nachvollziehbarkeit von Änderungen im System
Ändern Fachanwender die betroffenen Daten durch Standardtransaktionen, protokolliert das System diese Änderungen und bewahrt damit die ursprünglichen Daten auf, z. B. Änderungsbelege für Lieferant/Kunde/BP: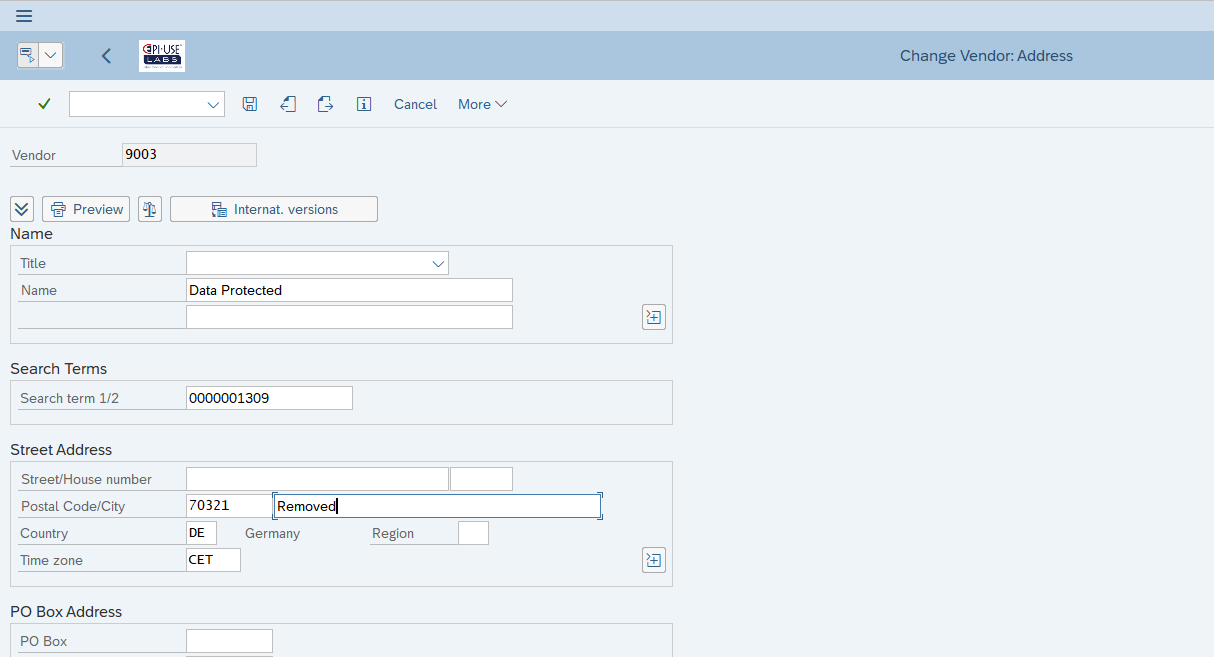
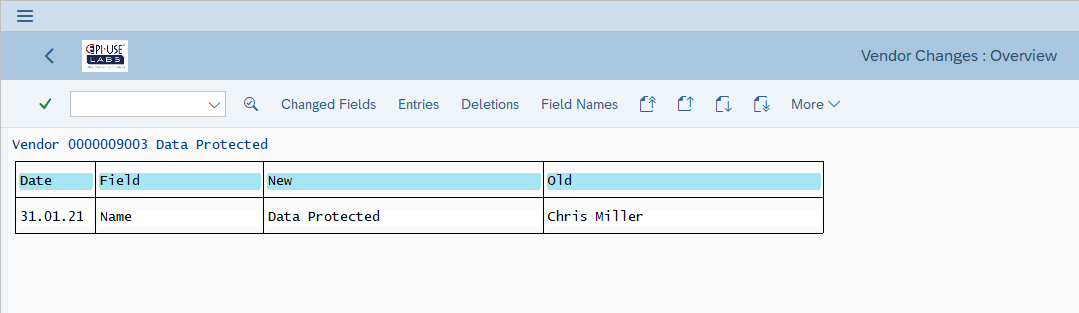
- Die Interkonnektivität von ERP-Systemen
Löschen wir stattdessen die Datensätze direkt auf Tabellenebene, führt das zu Inkonsistenzen im SAP System. Zum Beispiel könnten Kundenaufträge auf einen Kundenstammschlüssel referenzieren, der nicht mehr existiert.
Um diese beiden Probleme im Standard zu umgehen, werden die betroffenen Datensätze zum Löschen markiert und dann archiviert. Dadurch werden die Daten in eine separate Datei auf dem Betriebssystem verschoben. Von dort können die Daten weiterhin vom SAP-System gelesen, aber nicht mehr verändert werden. Das Archivieren von historischen personenbezogenen Daten ist nicht dazu gedacht, Daten aus dem SAP-System zu entfernen, trotzdem ist es durch das Löschen der Archivdatei aber möglich.
Das Problem dabei: der Archivierungsprozess erfordert, dass jede Transaktion, die auf die Stammdaten verweist, zuerst archiviert wird. Um diese Transaktionen wiederum zu archivieren, müssen zuerst alle Folgetransaktionen archiviert werden. Um beispielsweise Kundenstämme zu archivieren müssten zuerst Kundenaufträge archiviert werden. Hierfür müsste jedoch zuerst die Lieferung archiviert werden und das geht so weiter bis zu den Buchungsbelegen. Dieser Prozess wurde eben nicht dafür entwickelt, nur sensible oder personenbezogenen Daten zu entfernen.
SAP S/4HANA: Datenbereinigung und Archivierung
Bei der Vorbereitung oder dem Beginn einer S/4HANA Migration, werden Sie in der Regel irgendwann über die Themen Datenbereinigung und Archivierung sprechen. Beide Begriffe sollten Sie auf keinen Fall mit dem oben beschriebenen Problem verwechseln. Außer bei einem Greenfield Projekt, bei dem Altlasten einfach zurückgelassen werden können, ist mit dem Begriff Datenbereinigung selten die Bereinigung nicht benötigter Daten gemeint. Stattdessen wird dabei typischerweise vom CVI-Prozess (Customer/Vendor Integration) und der Deduplizierung von Stammdatensätzen oder die Korrektur von Formatierungsfehlern gesprochen.
Eine Archivierung wird für Brownfield Projekte in Betracht gezogen, um die Datenbankgröße des zukünftigen Systems zu verringern. Die größten Einsparungen können dabei durch das Entfernen großer Mengen an Bewegungsdaten erzielt werden, statt durch historische Stammdaten.
Die Alternative: Daten maskieren
Doch was, wenn es durch die Bereinigung des Backlogs keine großen Einsparmöglichkeiten beim Speicherplatz gibt? Und der Prozess weitere, schwierige Herausforderungen mit sich bringt und außerdem möglicherweise nützliche, nicht sensible Daten wie die geografische Verteilung der Kunden oder Gender-Reporting Optionen für historische Personaldaten entfernt werden? Gibt es nicht einen besseren Weg?
Lässt man das Unternehmen einfach die Daten, durch die eine Person identifiziert werden kann ändern, haben wir das Problem, dass die Änderung an sich nachzuverfolgen ist. Wenn wir stattdessen direkt auf Tabellenebene agieren und alles was sensibel oder identifizierend ist ersetzen, dann können wir dies aktiv beim Eintritt der Daten in unser System tun und benötigen keine weitere Änderungen.
Alle für das Reporting relevanten Informationen, können beibehalten werden. Und auch alle Abhängigkeiten aus Fremdschlüsselbeziehungen in Bewegungsdaten oder Referenzen aus verwandten Stammdaten (z. B. Adressen, PSP-Daten, Ansprechpartner) bleiben erhalten.
Praxisbeispiel 1: Lieferantenstamm
Hier sehen wir denselben Lieferanten wie oben. Jetzt haben wir jedoch sensible Felder in LFA1, LFB1, ADRC geschwärzt.
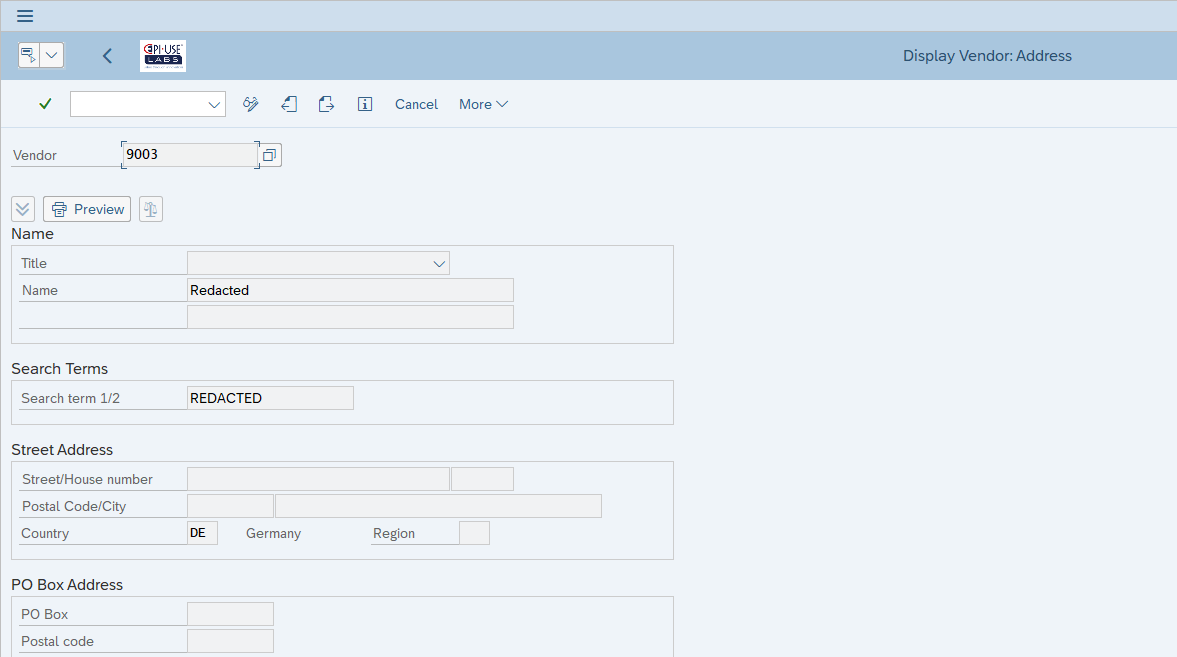

Auch alle Veränderungsbelege wurden entfernt, da Originalwerte vorhanden sein können.
Praxisbeispiel 2: Kundenstämme in Aufträgen
In diesem Beispiel sind die Stammdaten aus KNA1, ADRC usw., die über XD02 gepflegt werden, aufgrund der Verknüpfung in der Tabelle VPBA in der Transaktion Kundenauftrag (VA03) sichtbar. Wir brauchen in diesem Beispiel keine Änderungen am Auftrag vorzunehmen. Alle personenbezogenen Daten werden übernommen. Änderungen (ähnlich denen, die wir im ersten Beispiel für den Lieferanten vorgenommen haben und nun am Kundenstamm) sorgen also auch dafür, dass die Aufträge für diesen Kunden keine personenbezogenen Datenwerte mehr aufweisen.
Praxisbeispiel 3: Kundenspezifische Adressen in Aufträgen
Im vorherigen Blog habe ich mich mit benutzerdefinierten Adressen beschäftigt, entweder als Teil eines Kaufs als "Gast" oder wenn die Adresse aus dem Stammdatensatz für diesen speziellen Auftrag angepasst wurde. Jetzt sehen wir einen anderen Adressdatensatz, der mit der Bestellung in VPBA verknüpft ist und haben stattdessen diese Daten in ADRC programmatisch redigiert.
Das klingt einfach - wo ist der Haken?
Die Herausforderung beim Erstellen eigener Maskierungsprogramme ist die Vielzahl der gespeicherten Daten, die über das System verstreut sind. Diese zu finden ist nicht unmöglich, aber bei Änderungen der Geschäftsprozesse und bei zukünftigen Upgrades von SAP muss dies überprüft werden. Einige Beispiele sind:
- Änderungsbelege in der CDHR-Tabelle und im CDPOS-Cluster
Obwohl wir in unserem Maskierungsprozess keine Änderungsbelege erzeugen, kann es dennoch welche geben, und sie können echte Änderungen enthalten - z. B. eine Adressänderung eines Kunden. Sowohl die alten als auch die neuen Werte sind persönliche Daten für diesen Kunden. - ADRC, ADR2, ADCP, ADRP, etc.
Je nach Customizing des Systems und Art der Adressdaten können unterschiedliche Felder in verschiedenen Tabellen diese personenbezogenen Daten speichern. Es ist wichtig, sie alle aufzuspüren, aber nur die vorgesehenen Adressen zu verändern und nicht versehentlich z. B. eine Customising-Adresse. - Clusterdaten
Transparente Tabellen sind in der Regel einfach zu handhaben und sogar Cluster wie CDPOS, bei denen der Schlüssel außerhalb der rohen Clusterdaten liegt. Aber in einigen Fällen (wie bei den HCM-Daten, die ich im nächsten Blog behandeln werde) ist der eigentliche Bezeichner schwieriger zu erkennen - z.B. die Mitarbeiternummer im PCL2-Cluster. Aber auch der Ort, an dem sich die personenbezogenen Daten im Cluster befinden, kann von System zu System und sogar von Datensatz zu Datensatz variieren, je nach Land des Mitarbeiters beispielweise oder anderen Eigenschaften des jeweiligen Datensatzes im Geltungsbereich.
Wie maskieren wir bei EPI-USE Labs?
Wir haben eine Software entwickelt, die von Unternehmen direkt genutzt werden kann, um eigene Maskierungen vorzunehmen. Dies kann entweder reaktiv auf einzelne Anfragen oder als Teil einer automatischen, periodischen Anwendung einer Aufbewahrungsfrist geschehen. Wir bieten auch Dienstleistungen an, um bei der Bewältigung der ersten Bereinigung von Daten zu helfen. Kontaktieren Sie uns, wenn unsere Experten Sie unterstützen können.
So erreichen Sie mit minimalen Aufwand, die Compliance Anforderungen zur Minimierung von historischen Daten.