La privacidad de los datos es una cuestión a la que se presta mucha atención por lo que las organizaciones deben plantearse cómo cumplir las normativas que protegen los derechos de las personas respecto a la privacidad de los datos. En Europa, el RGPD es la legislación que se incorporó con el fin de establecer una nueva norma para regular la privacidad de los datos. No obstante, muchos países de todo el mundo han actualizado su legislación para incorporar la privacidad de los datos como, por ejemplo, la Ley POPI en Sudáfrica, la LGPD en Brasil y la CCPA en California.
La privacidad de los datos es una cuestión a la que se presta mucha atención por lo que las organizaciones deben plantearse cómo cumplir las normativas que protegen los derechos de las personas respecto a la privacidad de los datos. En Europa, el RGPD es la legislación que se incorporó con el fin de establecer una nueva norma para regular la privacidad de los datos. No obstante, muchos países de todo el mundo han actualizado su legislación para incorporar la privacidad de los datos como, por ejemplo, la Ley POPI en Sudáfrica, la LGPD en Brasil y la CCPA en California.
Es muy probable que, si está leyendo este blog, ya esté examinando las necesidades de seguridad de datos en su organización y que haya empezado a aplicar algunas soluciones para abordar algunas de sus inquietudes. En esta ocasión, me gustaría compartir parte de la experiencia que he adquirido en mi trabajo para EPI-USE Labs en múltiples proyectos de privacidad de datos, concretamente en el contexto de los sistemas SAP®.
Por lo general, hay tres posturas claras a la hora de elaborar los requisitos de privacidad de los datos.
-
Responsables de pruebas y propietarios de productos: la prioridad clara es poder probar los procesos con datos ‘reales’ (lo cual cuenta con todos los imprevistos de la producción, incluidos aspectos que no son totalmente correctos).
-
Equipos de protección de datos: la prioridad es que no exista ninguna información personal identificable (PII) fuera de la producción.
-
Equipos de TI e infraestructura: la prioridad reside en la rapidez y la eficiencia para entregar los datos copiados y codificados con la mínima interrupción en el landscape que no es de producción.
Estos tres puntos de vista contradictorios suponen un reto específico a la hora de ofrecer un entorno de operaciones de desarrollo seguro y útil. En esta publicación, voy a analizar las dificultades a la hora de proporcionar los datos alineados y similares a los de producción que los gestores de pruebas desean ver.
Para ello, hay dos escenarios de datos a tener en cuenta:
Escenario 1
Por ejemplo, un empleado que trabaja en el departamento de compras con números de identificación fiscal en España. Un empleado es precisamente lo más habitual cuando se piensa en la información de identificación personal. Para desglosarlo y mostrar algunos de los procesos estándar de SAP que almacenan datos sensibles, presentamos un diagrama de alto nivel que muestra la relación de datos en el objeto de empleado.
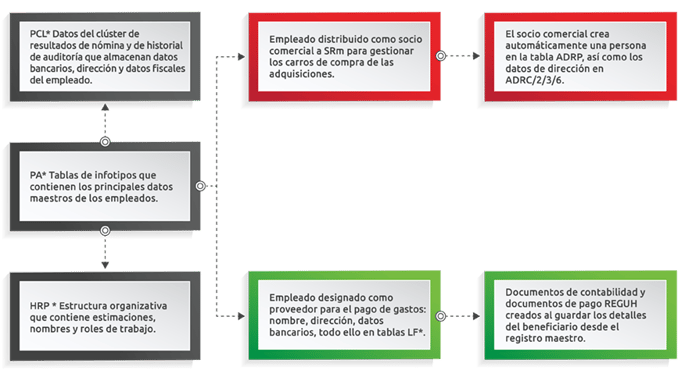
En el modelo de datos estándar de SAP puede haber centenares de campos de datos sensibles. Además, tendría personalizaciones realizadas a través del historial, donde se almacenan copias adicionales de los datos. Todos estos elementos de datos deben ser rellenados por una persona al principio y, por tanto, ello conlleva riesgo de errores en la introducción. Con el paso de los años, es probable que las correcciones, los programas de limpieza y las correcciones manuales de la empresa puedan provocar una falta de sincronización total de los datos
De este modo, el sistema se integra y se conecta, pero también crea potencialmente más complejidad si se busca enmascarar o desordenar los datos para cumplir con la privacidad de los mismos.
Escenario 2
Un ejemplo solicitado por un cliente para enmascarar el número de IVA en España y Portugal. En este caso, la regla de negocio es muy simple. El campo STCEG en KNA1 debe ser el valor concatenado del país y el campo STCD1 para ese cliente:
| KUNNR | LAND1 | STCD1 - KNA1 | STCD2 - KNA1 | STCEG - KNA1 |
| 0000000001 | ES | A12345678 | - | ESA12345678 |
A continuación se muestra un análisis de los datos que nos ayudará a comprender la variación de los mismos. El análisis examina la longitud y la coherencia de esta regla antes de cualquier actividad de anonimización de datos. A partir de este análisis, he encontrado:
-
Seis distintas longitudes de números de identificación fiscal solamente en España.
-
Un 10 % de datos que no coincidían con los originales.
-
Un 20 % más de ejemplos en los que un campo estaba en blanco.
-
Un 25 % en el que había reglas de alineación, y no el requisito previsto por el cliente.
-
Más de 1000 distintos escenarios de coherencia cuando se superponen países adicionales y se considera la integración entre sistemas con CRM.
En definitiva, solo el 35 % de los datos se ajustaban al requisito que el cliente había indicado como el ‘mundo ideal’ o el mapeo más tradicional.
¿Cuál es la repercusión de todo esto?
Volviendo a mis tres prioridades originales, para ofrecer datos de producción reales, enmascarados para enfrentarse a cuestiones de seguridad y creados también de forma eficiente, es preciso saber cómo se vinculan los datos y comprender cómo la calidad de los datos desempeña una función en el sistema.
-
En el primer ejemplo, se ve que si nos limitamos a atender los datos obvios de los infotipos de los empleados, quedará una gran cantidad de datos sensibles relacionados sin anonimizar.
-
En el segundo ejemplo, en el que únicamente teníamos que fijar los dos campos de impuestos, se necesitaría una lógica para atender a 1163 escenarios. El tiempo de ejecución de esto a la hora de comparar y tomar decisiones sería mucho mayor que el tiempo de inactividad admisible para una actualización del sistema y una codificación.
En EPI-USE Labs, colaboramos con los clientes para analizar los datos de su sistema SAP y predecir dónde pueden surgir problemas en los datos. También proporcionamos posibles soluciones para dar el mejor resultado posible a cada propietario del proceso.
Eche un vistazo a este seminario web en el que trato el análisis de datos en SAP con fines de seguridad en entornos de no producción. En él también demuestro algunos de los programas que utilizamos durante un taller y análisis de privacidad de datos.