
Data privacy is a topic that gets a lot of focus and organisations need to consider how to comply with regulations that protect an individual’s rights to data privacy. In Europe, GDPR is the legislation that was brought in to set a new standard for regulating data privacy, but around the globe many countries have updated their legislation to incorporate data privacy, for example: POPI Act in South Africa, LGPD in Brazil and CCPA in California.

La confidentialité des données est un sujet qui attire beaucoup d’attention : les organisations doivent prendre en compte le respect des réglementations destinées à protéger le droit d’un individu à la confidentialité de ses données. En Europe, le RGPD est la législation qui a été adoptée pour définir une nouvelle norme de régulation de la confidentialité des données, mais à travers le monde, de nombreux pays ont adapté leur législation pour inclure la confidentialité des données, comme le POPI Act en Afrique du Sud, le LGPD au Brésil ou encore le CCPA en Californie.
Si vous lisez ce blog, vous avez certainement déjà commencé à examiner les besoins en sécurité des données de votre organisation et à implémenter des solutions pour répondre à certaines problématiques. Aujourd’hui, j’aimerais partager avec vous l’expérience que j’ai acquise en travaillant avec EPI-USE Labs sur de nombreux projets de confidentialité des données, en particulier dans le contexte de systèmes SAP®.
Généralement, trois voix se distinguent clairement lors des ateliers visant à définir les exigences de confidentialité des données :
-
Les responsables des tests et product owners : la priorité est de pouvoir tester les processus sur des données « réelles » (ce qui est tributaire des aléas de la production, notamment les données qui ne sont pas totalement correctes).
-
Les équipes de protection des données : la priorité est qu’il n’existe aucune information d’identification personnelle (PII) en dehors de la production.
-
Les équipes IT et d’infrastructure : la priorité est mise sur la rapidité et l’efficacité de la livraison de données copiées et masquées avec une interruption minimale de l’environnent non productif.
Ces trois visions divergentes représentent un défi spécifique pour fournir un environnement opérationnel de développement sécurisé et fonctionnel. Au cours de cette publication, je veux explorer les difficultés rencontrées pour fournir les données productives que les responsables des tests attendent.
Voici deux scénarios de données à envisager :
Scénario 1
Un exemple simple d’un employé qui travaille dans le service des achats avec des numéros fiscaux en Espagne. L’employé est un point de concentration courant lorsqu’il est question des informations d’identification personnelle. Pour décomposer et afficher certains des processus SAP standard qui enregistrent les données sensibles, voici un diagramme de haute qualité qui illustre la relation entre les données dans l’objet Employé.
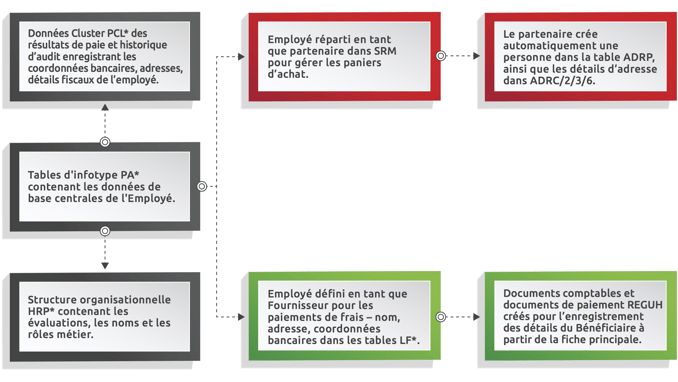
Le modèle de données SAP standard peut contenir des centaines de champs de données sensibles. Par ailleurs, il contiendrait les personnalisations effectuées au fil du temps, dans lesquelles ont été enregistrées des copies supplémentaires des données. Tous ces éléments de données doivent être renseignés par une personne au départ et présentent, ainsi, un risque d’erreur de saisie humaine. Au fil des années, il est probable que les corrections, les programmes de nettoyage et les corrections manuelles réalisés par l’entreprise aient désynchronisé les données.
La force du système réside dans son intégration et sa connexion, mais cela crée également potentiellement plus de complexité si vous essayez de masquer ou d’anonymiser les données afin de respecter la confidentialité des données.
Scénario 2
Un exemple de demande client visant à masquer le numéro de TVA en Espagne et au Portugal. Dans ce scénario, la règle de gestion est très simple : le champ STCEG dans KNA1 doit correspondre à la valeur concaténée du pays et le champ STCD1 à celle du client :
| KUNNR | LAND1 | STCD1 - KNA1 | STCD2 - KNA1 | STCEG - KNA1 |
| 0000000001 | ES | A12345678 | - | ESA12345678 |
Voici une analyse des données pour nous aider à comprendre la variation des données. L’analyse se concentre sur la longueur et la cohérence de cette règle avant toute activité d’anonymisation des données. À partir de cette analyse, j’ai trouvé :
-
Six longueurs de numéros fiscaux différentes rien que pour l’Espagne
-
10 % des données ne correspondaient pas aux données d’origine
-
20 % supplémentaires d’exemples contenant un champ vide
-
25 % contenant des règles d’alignement – mais pas les exigences client attendues
-
Plus de 1 000 scénarios de cohérence différents dans lesquels les pays supplémentaires étaient superposés et une intégration inter-systèmes avec CRM était prise en compte.
Au final, seules 35 % des données correspondaient aux exigences données par le client comme mappage « idéal » ou le plus traditionnel possible.
Alors, quel est l’impact de ces données ?
Si l’on revient aux trois priorités initiales visant à fournir des données de production réelles, qui sont masquées pour répondre aux problèmes de sécurité et créées de manière efficace, il est nécessaire de connaître les relations entre les données et de comprendre en quoi la qualité des données joue un rôle dans le système.
-
Dans le premier exemple, vous voyez que traiter uniquement les données d’infotype d’employé évidentes laissera un nombre massif de données sensibles associées sans anonymisation.
-
Dans le second exemple, dans lequel il a suffi de définir les deux champs de taxe, cela demanderait une certaine logique pour traiter les 1 163 scénarios. La durée d’exécution de cette opération lors de la comparaison et de la prise de décisions serait bien supérieure au temps d’arrêt autorisé pour un rafraîchissement et une anonymisation du système.
Chez EPI-USE Labs, nous travaillons avec nos clients pour analyser les données dans leur système SAP et prévoir l’apparition des problèmes dans les données. Nous fournissons également des solutions potentielles pour offrir à chaque propriétaire de processus le meilleur résultat possible.

Leave a Comment: