If you haven’t previously – and aren’t currently – dealing with ‘display only’ SAP systems or data that really should be decommissioned, you soon will be. With the tightening of data compliance laws worldwide happening just before the biggest SAP ecosystem mass transformation period in its history, there will be legacy data and systems that need to be cost-effectively sunsetted at all organisations that run SAP.
‘Archiving’ by table or by business object
In the first blog in this series, I referenced the complexity of the SAP® data model. There are very deep interrelationships between different tables, sometimes via an intuitive link (for example, an Address number appearing in the tables for the Business Partner, Customer or Vendor). However, there are cases an SAP user would never be aware of when the link is via an internal number.
When talking about ‘decommissioning’, the term ‘archiving’ often crops up. The traditional SAP archiving mechanism is simply to offload the data from the database to a physical file. So, when someone calls a transaction code to view that data, the ABAP application layer knows that rather than routing its query to the database, it must query the relevant files to read the information.
But the files are not organised by logical groups of business data. That is not what the ABAP application layer needs. It simply wants to open the file and search for key XYZ rather than making an SQL select on a database table for key XYZ. The response time will typically be much slower ‒ and, of course, archived data cannot change ‒ but otherwise the mechanism is the same. When it comes to decommissioning, the archive files are no more useful than downloading the individual table contents from the database. How will you then put those tables together? The business logic needed is not with the files; that was still in the SAP system and that’s no longer going to be available.
Reaping the benefits of Data Sync Manager SAP Extractor
To preserve the ability to view the ‘instance’ of the business object, we don’t want files for one table with multiple business keys. Rather, we want files with all table rows for a specific key or set of keys. We also require a meta-data definition that not only tells us how to combine the different table rows to show the instance of the business object, but also how this business object may relate or link to other objects.
For example, when viewing a Sales Order, there is a key for the Material referenced in the line item. This allows the data to be combined to show a material description (part of the material master object) when viewing the sales order itself. This is where the Data Sync Manager™ SAP Extractor comes into play. Data is selected by keys and exported with all relevant table contents and a meta-data definition. The Intellectual Property that is being leveraged has been built and refined over the last two decades at over 700 SAP installations spanning the globe and many industries. It has been used to carve out new SAP systems, merge data into systems and most prominently provision or anonymise test data.
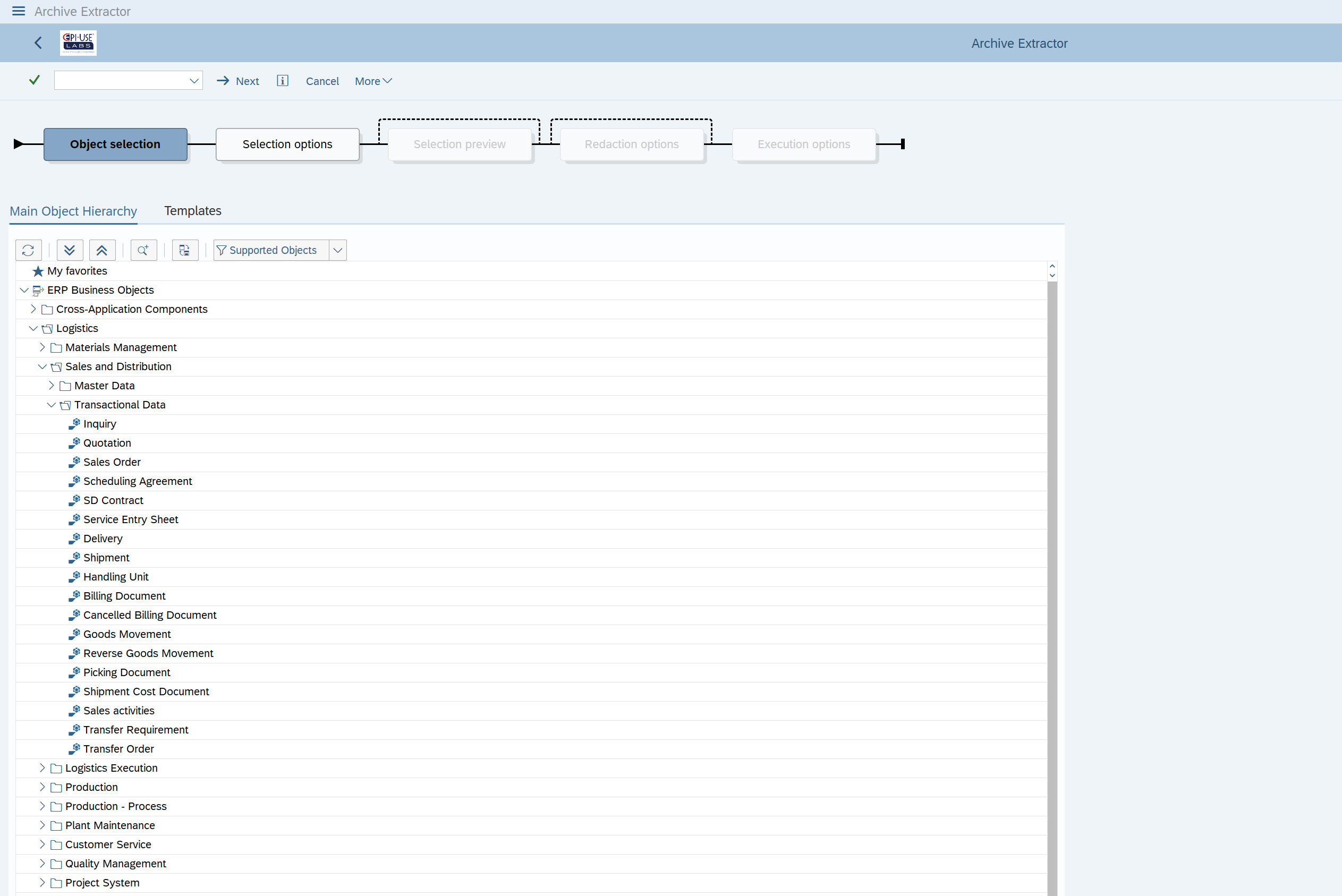
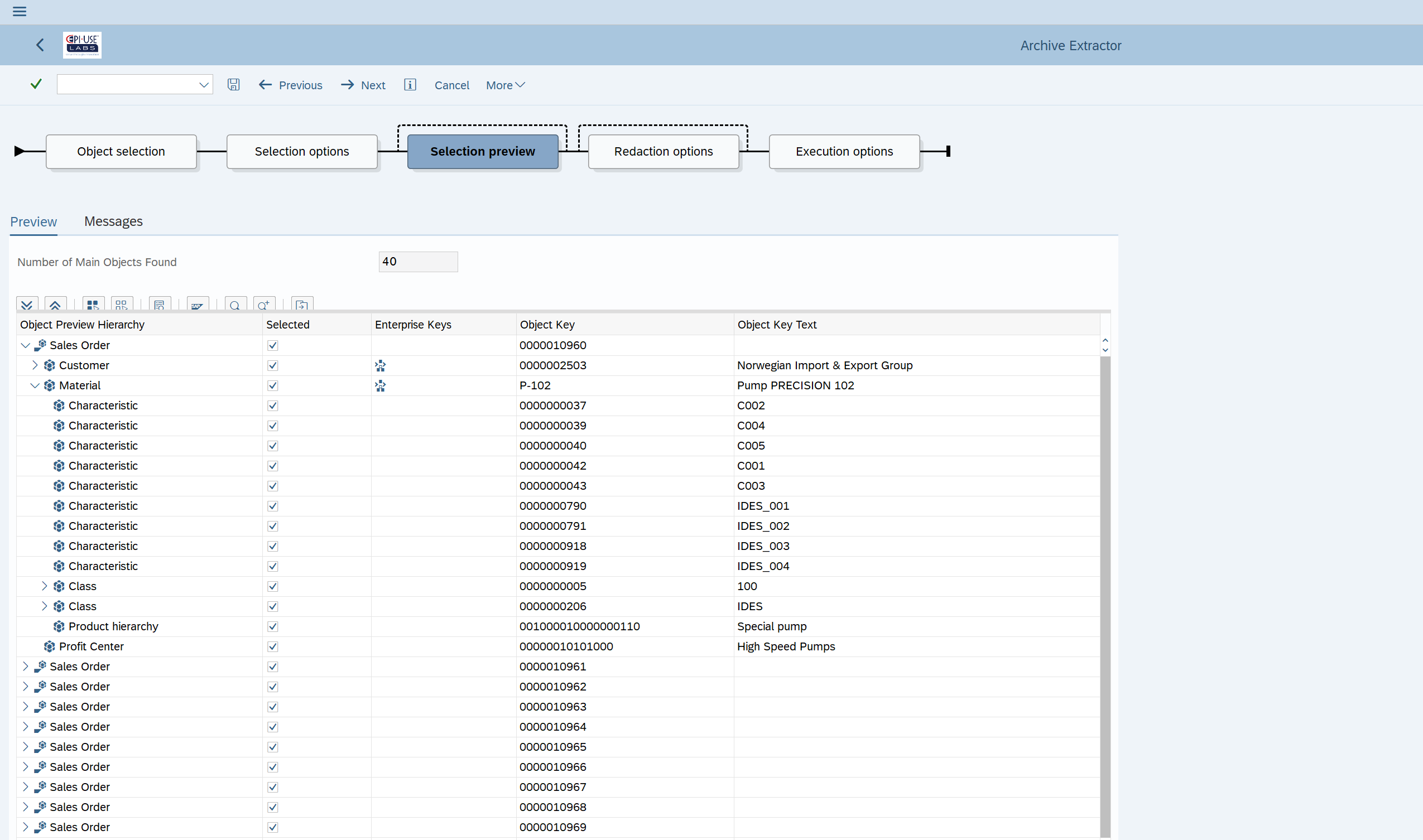
The extraction also includes some of the label information for fields with specific domain values. The user will want to see the description, not the arbitrary code that’s stored in the field itself. In some cases, the codes may get their description from a related configuration table, and can even be dependent on levels of configuration. For example, a wage type description can differ depending on where the employee works in the business. And, of course, there are also language versions of these descriptions stored in the configuration table.
That sounds easy on the extraction side. What’s the catch?
So far, we’ve looked at simple, transparent, tables in the database. There are also more complex table types, such as cluster tables. In essence, you can think of the cluster as being a normal table row but with one or more fields that are special compressed data records, like a zip file. To interpret the zipped data, you need to know the format of the cluster, and this can differ for different rows. For example, the actual tables inside the cluster for payroll data vary between different country versions. There are simpler uses of clusters for performance or space saving. The RFBLG cluster has been used for a long time in many SAP versions to manage some of the accounting documents. Here, the key of the table sits in the transparent part but, until the data is ‘unzipped’ from the cluster, we don’t know which table the data is actually in. There are several variations on this and any solution that is attempting to decommission SAP will need to cater for many of them.
Unstructured data in your SAP systems
The data we’ve discussed so far is what is termed ‘structured’ data: the same meta-data model repeated again and again with the same table rows linking together to encapsulate the data. We then have to consider the unstructured data that has been generated from, or placed in, your SAP systems. There are several different ways to store documents in SAP but the most common is via a Content Server. The basic premise is that the Relational Database Management System sitting underneath your SAP application was not particularly well suited to storing Word documents, PDFs and so on. So, SAP introduced Archive Link which allowed organisations to push this content out to a separate database or file system location. This provided the facility to store the data more efficiently, then pass information in real time to the SAP application server and on to the GUI when a user requested to see the document. It will be necessary to formulate a plan to mass download these documents and make them available after SAP is decommissioned. This may be approached via coding in the SAP layer or, alternatively, using RPA or ‘Bot’ technology.
Unstructured data can also be stored directly in the SAP database, via the Generic Object Services (GOS) capability. This is a small button which can appear at the top left of many transactions to denote that GOS is available. Here, the user can make public or private notes or use it to upload a Word or PDF document.
Invisible data?
And then, there’s the data that isn’t really there. Well, not consistently in any case. There are some quite high-volume data types generated from structured data, put through a template or form, and temporarily stored before being sent out. This can include payslips, payment notifications, generated invoices and many other document types. It’s a challenging mix of structured data and unstructured layout combined to give a very identifiable layout. Most people assume it’s sitting as a PDF somewhere in SAP or a content server, but it is not. Payslips and anything which uses SAP Forms are the main areas to consider.
OK, we’ve got it. Now where do we take it?
The next five years will see an unprecedented number of SAP systems decommissioned. During that time, the move to the cloud (in 2018, Cisco projected that by now 95% of total data centre traffic would be cloud traffic) and SaaS is expected to continue unabated. So, when we decided to build a solution for dealing with old systems and data, we wanted to use modern technology that would fit with where our clients are going, not where they’re coming from. Archive Central is consumed as a SaaS application and with it, you will never have any other bills or unexpected costs. We can accommodate geographical restrictions or preferences and there is flexibility around the choice of hyper-scaler (I won’t tell you our favourites since they all have legal departments that dwarf our organisation ten-fold).
The underlying technology platform itself is not actually a completely new one. As an organisation, we have over 1,000 clients and became disillusioned with what was available for managing our interactions with them. We moved from an ‘off-the-shelf’ provider for ticketing and support many years ago to our own platform, Client Central. At the latest count, it has 19,000 users with over 400 active in the last month. The Archive Central platform shares the base and benefits from new functionality and features as they become available. It is deployed completely separately in a dedicated instance per client, benefitting from all the security protections of the hyper-scaler and our own complementary ones. Both Client Central and Archive Central go through annual penetration testing projects by accredited external organisations.
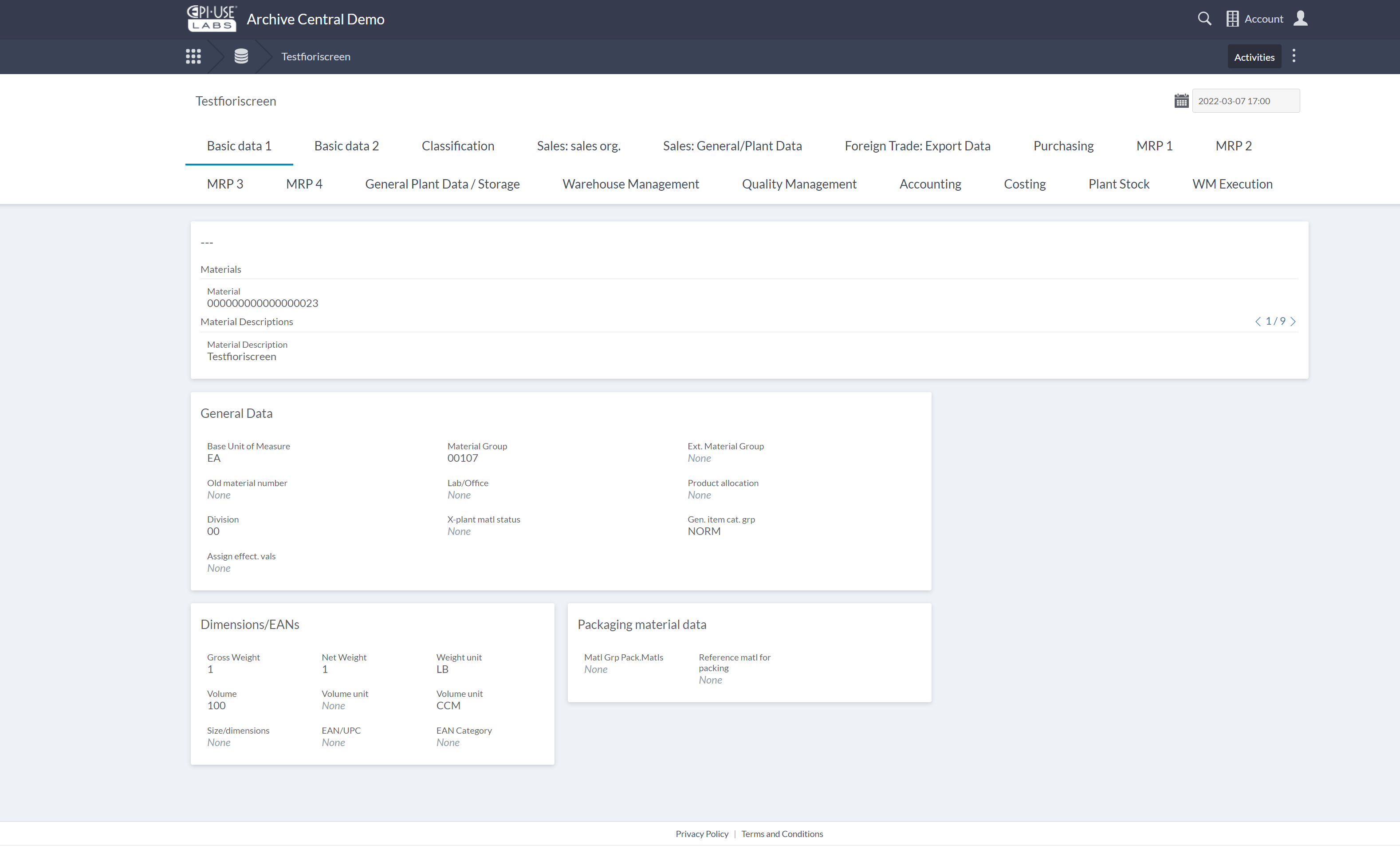
Archive Central supports non-SAP legacy system decommissioning but its real value comes in the SAP space. It has been specifically designed to manage the complex and verbose SAP data model with input from specialists. Extracts from SAP can be ingested automatically and turned into Collections with automated processing decisions applied (such as only showing fields with data for at least one key ‒ additional meta-data is in the background and visible at the click of a button).
The meta-data from SAP is already inherent in the collection and even the links between collections for related objects (like the Sales Order and Material example mentioned earlier). Anyone with relevant role-based permissions can alter the layout without any technical knowledge or skills. Unstructured data can be ingested and linked to the structured data for easy viewing and there are SAP-based utilities for extracting the most common types.
How can we help with decommissioning?
Our teams take responsibility for the entire SAP decommissioning process: an analysis of the SAP system to understand the data in use; workshops to agree and finalise the blueprint; extraction and ingestion; and making tweaks to the layout after the User Acceptance Testing.