Wenn Sie sich bisher noch nicht mit SAP-Systemen beschäftigt haben, die „nur angezeigt“ werden, oder mit Daten, die eigentlich stillgelegt werden sollten, werden Sie es bald tun. Mit der Verschärfung der weltweiten Gesetze zur Einhaltung von Datenschutzbestimmungen kurz vor der größten Massenumstellung des SAP-Ökosystems in seiner Geschichte wird es in allen Unternehmen, die mit SAP arbeiten, Altdaten und -systeme geben, die kosteneffizient aus dem Verkehr gezogen werden müssen.
„Archiveren“ von Tabellen oder Businessobjekten
Im ersten Blog dieser Reihe habe ich auf die Komplexität des SAP®-Datenmodells hingewiesen. Es gibt sehr weitreichende Verknüpfungen zwischen verschiedenen Tabellen, manchmal über eine intuitive Verbindung (z. B. eine Adressnummer, die in den Tabellen für den Geschäftspartner, Kunden oder Lieferanten erscheint) und dann Fälle, in denen ein SAP-Benutzer nie etwas davon mitbekommen würde, wenn die Verknüpfung über eine interne Nummer erfolgt.
Wenn von „Stilllegung“ die Rede ist, taucht häufig der Begriff „Archivierung“ auf. Der traditionelle SAP-Archivierungsmechanismus besteht einfach darin, die Daten aus der Datenbank in eine physische Datei auszulagern. Wenn also jemand einen Transaktionscode aufruft, um diese Daten einzusehen, weiß die ABAP-Anwendungsschicht, dass sie ihre Anfrage nicht an die Datenbank weiterleiten, sondern die entsprechenden Dateien abfragen muss, um die Informationen zu lesen.
Von den Vorteilen des Data Sync Manager SAP Extractor profitieren
Um die Möglichkeit zu erhalten, die „Instanz“ des Geschäftsobjekts anzuzeigen, wollen wir keine Dateien für eine Tabelle mit mehreren Geschäftsschlüsseln. Vielmehr wollen wir Dateien mit allen Tabellenzeilen für einen bestimmten Schlüssel oder eine bestimmte Gruppe von Schlüsseln. Außerdem benötigen wir eine Metadatendefinition, die nicht nur angibt, wie die verschiedenen Tabellenzeilen kombiniert werden, um die Instanz des Geschäftsobjekts darzustellen, sondern auch, wie sich dieses Geschäftsobjekt auf andere Objekte beziehen oder mit ihnen verknüpfen kann.
Bei der Anzeige eines Kundenauftrags gibt es zum Beispiel einen Schlüssel für das Material, auf das in der Position verwiesen wird. Dadurch können die Daten kombiniert werden, um eine Materialbeschreibung (Teil des Materialstammobjekts) zu sehen, wenn der Kundenauftrag selbst angezeigt wird. An dieser Stelle kommt der Data Sync Manager™ SAP Extractor ins Spiel. Die Daten werden nach Schlüsseln ausgewählt und mit allen relevanten Tabelleninhalten und einer Metadatendefinition exportiert. Das geistige Eigentum, das hier zum Einsatz kommt, wurde in zwei Jahrzehnten in über 700 SAP-Installationen auf der ganzen Welt und in vielen Branchen entwickelt und verfeinert. Es wurde verwendet, um neue SAP-Systeme zu entwickeln, Daten in Systemen zusammenzuführen und vor allem Testdaten bereitzustellen oder zu anonymisieren.
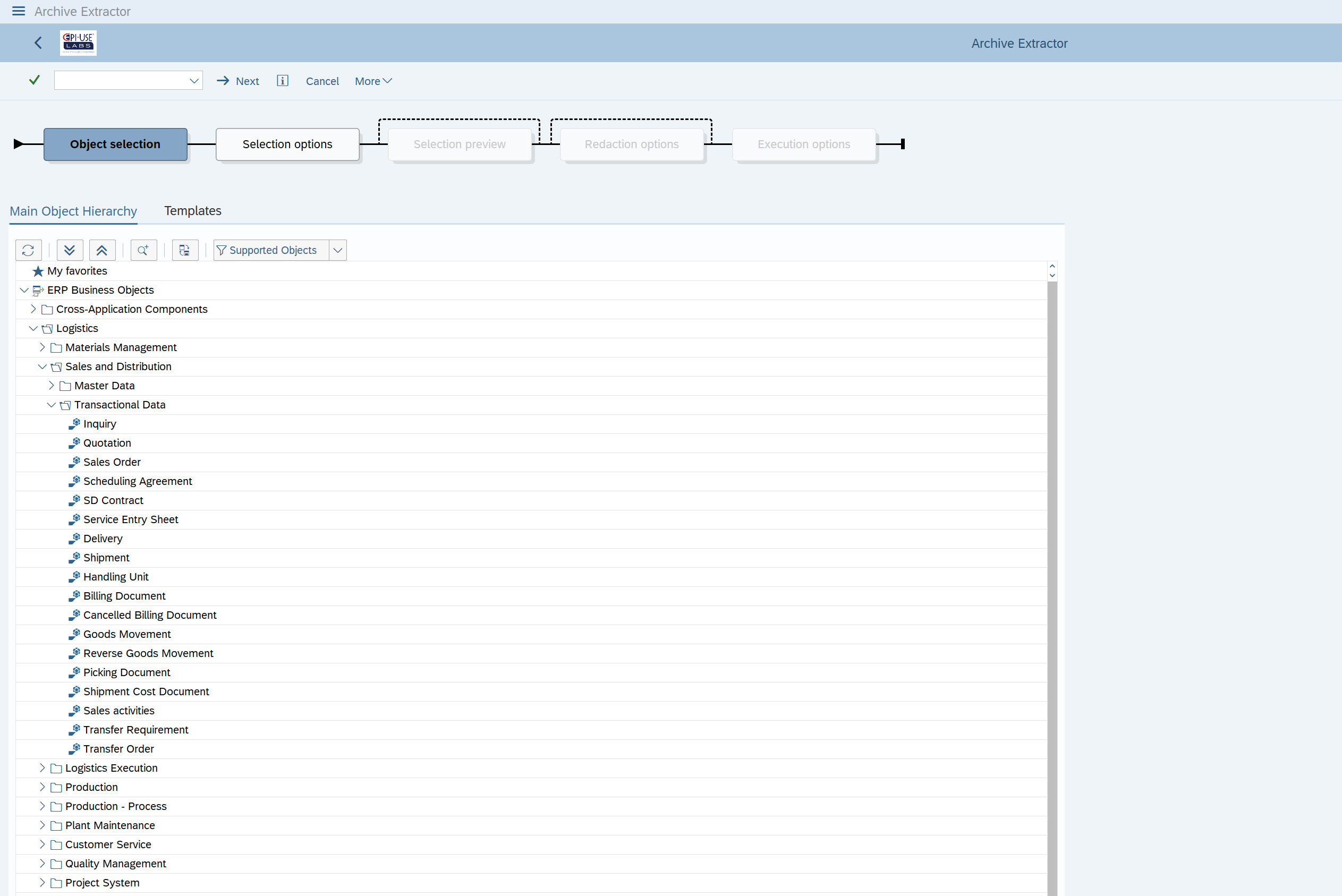
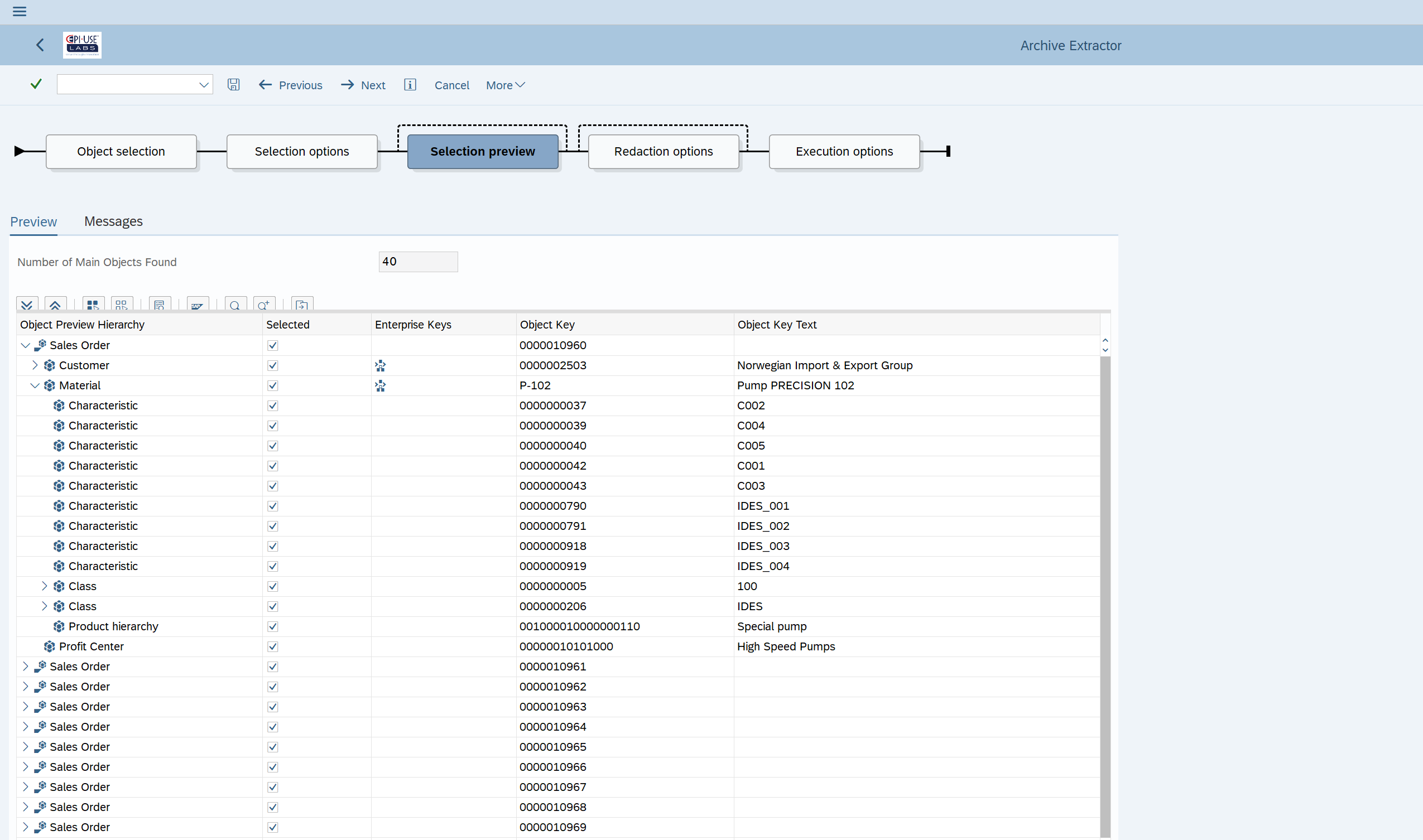
Die Extraktion umfasst auch einen Teil der Beschriftungsinformationen für Felder mit bestimmten Domänenwerten. Der Benutzer möchte die Beschreibung sehen, nicht den willkürlichen Code, der in dem Feld selbst gespeichert ist. In einigen Fällen erhalten die Codes ihre Beschreibung aus einer zugehörigen Konfigurationstabelle und können sogar von den Konfigurationsebenen abhängig sein. Die Beschreibung einer Lohnart kann davon abhängen, wo der Mitarbeiter im Unternehmen arbeitet. Und natürlich gibt es auch Sprachversionen dieser Beschreibungen, die in der Konfigurationstabelle gespeichert sind.
Das klingt zu einfach: Wo ist der Haken?
Bisher haben wir uns mit einfachen, transparenten Tabellen in der Datenbank befasst. Es gibt auch komplexere Tabellentypen, wie z. B. Clustertabellen. Im Wesentlichen kann man sich eine Cluster wie eine normale Tabellenzeile vorstellen, die jedoch ein oder mehrere Felder enthält. Genauer handelt es sich um spezielle komprimierte Datensätze, wie bei einer Zip-Datei. Um die komprimierten Daten zu interpretieren, müssen Sie das Format des Clusters kennen und das kann für verschiedene Zeilen unterschiedlich sein. Die eigentlichen Tabellen innerhalb des Clusters für die Lohn- und Gehaltsabrechnungsdaten variieren beispielsweise zwischen den verschiedenen Länderversionen. Es gibt einfachere Verwendungen von Clustern zur Leistungssteigerung oder Platzeinsparung. Der RFBLG-Cluster wird seit langem in vielen SAP-Versionen verwendet, um einen Teil der Buchhaltungsbelege zu verwalten. Hier befindet sich der Schlüssel der Tabelle im transparenten Teil, aber bis die Daten aus dem Cluster „entpackt“ werden, wissen wir nicht, in welcher Tabelle sich die Daten tatsächlich befinden. Es gibt verschiedene Varianten, und jede Lösung, die versucht, SAP außer Betrieb zu nehmen, muss viele von ihnen berücksichtigen.
Unstrukturierte Daten im SAP-System
Bei den Daten, die wir bisher besprochen haben, handelt es sich um so genannte „strukturierte“ Daten: dasselbe Metadatenmodell, das sich immer wieder mit denselben Tabellenzeilen wiederholt, die zur Datenkapselung miteinander verknüpft sind.
Nun müssen wir uns mit unstrukturierten Daten befassen, die aus Ihren SAP-Systemen erzeugt oder in diese eingegeben wurden. Es gibt verschiedene Möglichkeiten, Dokumente in SAP zu speichern, aber die gebräuchlichste ist die Verwendung eines Content-Servers. Der Grundgedanke ist, dass das relationale Datenbankmanagementsystem, das unter Ihrer SAP-Anwendung liegt, nicht besonders gut für die Speicherung von Word-Dokumenten, PDF-Dateien usw. geeignet war. Daher führte SAP Archive Link ein, mit dem Unternehmen diese Inhalte in eine separate Datenbank oder ein Dateisystem auslagern konnten. Dies ermöglichte eine effizientere Speicherung der Daten und die Weitergabe von Informationen in Echtzeit an den SAP-Anwendungsserver und an die grafische Benutzeroberfläche, wenn ein Benutzer das Dokument anzeigen wollte. Es wird notwendig sein, einen Plan für den Massendownload dieser Dokumente zu formulieren und sie nach der Außerbetriebnahme von SAP verfügbar zu machen. Dies kann durch Kodierung in der SAP-Schicht oder alternativ durch den Einsatz von RPA oder 'Bot'-Technologie erfolgen.
Unstrukturierte Daten können auch direkt in der SAP-Datenbank gespeichert werden, und zwar über die Funktion Generic Object Services (GOS). Dies ist eine kleine Schaltfläche, die in vielen Transaktionen oben links erscheinen kann, um die Verfügbarkeit von GOS anzuzeigen. Hier kann der Benutzer öffentliche oder private Notizen machen oder ein Word- oder PDF-Dokument hochladen.
Unsichtbare Daten?
Und dann sind da noch die Daten, die nicht wirklich vorhanden sind. Nun, nicht in jedem Fall. Es gibt einige recht umfangreiche Datentypen, die aus strukturierten Daten erzeugt, durch eine Vorlage oder ein Formular geleitet und vor dem Versand zwischengespeichert werden. Dazu können Gehaltsabrechnungen, Zahlungsbenachrichtigungen, erstellte Rechnungen und viele andere Dokumenttypen gehören. Es handelt sich um eine schwierige Mischung aus strukturierten Daten und unstrukturiertem Layout, die ein sehr identifizierbares Layout ergibt. Die meisten Leute gehen davon aus, dass sie als PDF irgendwo in SAP oder einem Content Server liegen, aber das ist nicht der Fall. Gehaltsabrechnungen und alles, was SAP Forms verwendet, sind die wichtigsten Bereiche, die zu berücksichtigen sind.
OK, jetzt haben wir es. Wohin sollen wir es jetzt bringen?
In den nächsten fünf Jahren wird eine noch nie dagewesene Anzahl von SAP-Systemen außer Betrieb genommen werden. In dieser Zeit wird die Verlagerung in die Cloud (2018 prognostizierte Cisco, dass mittlerweile 95 % des gesamten Datenverkehrs in Rechenzentren aus der Cloud stammen) und SaaS voraussichtlich unvermindert weitergehen. Als wir also beschlossen, eine Lösung für den Umgang mit alten Systemen und Daten zu entwickeln, wollten wir eine moderne Technologie einsetzen, die zu dem passt, wohin unsere Kunden gehen, nicht woher sie kommen. Archive Central wird als SaaS-Anwendung genutzt, sodass keine weiteren Rechnungen oder unerwarteten Kosten auf Sie zukommen werden. Wir können geografische Beschränkungen oder Präferenzen berücksichtigen, und es besteht Flexibilität bei der Wahl des Hyper-Scalers.
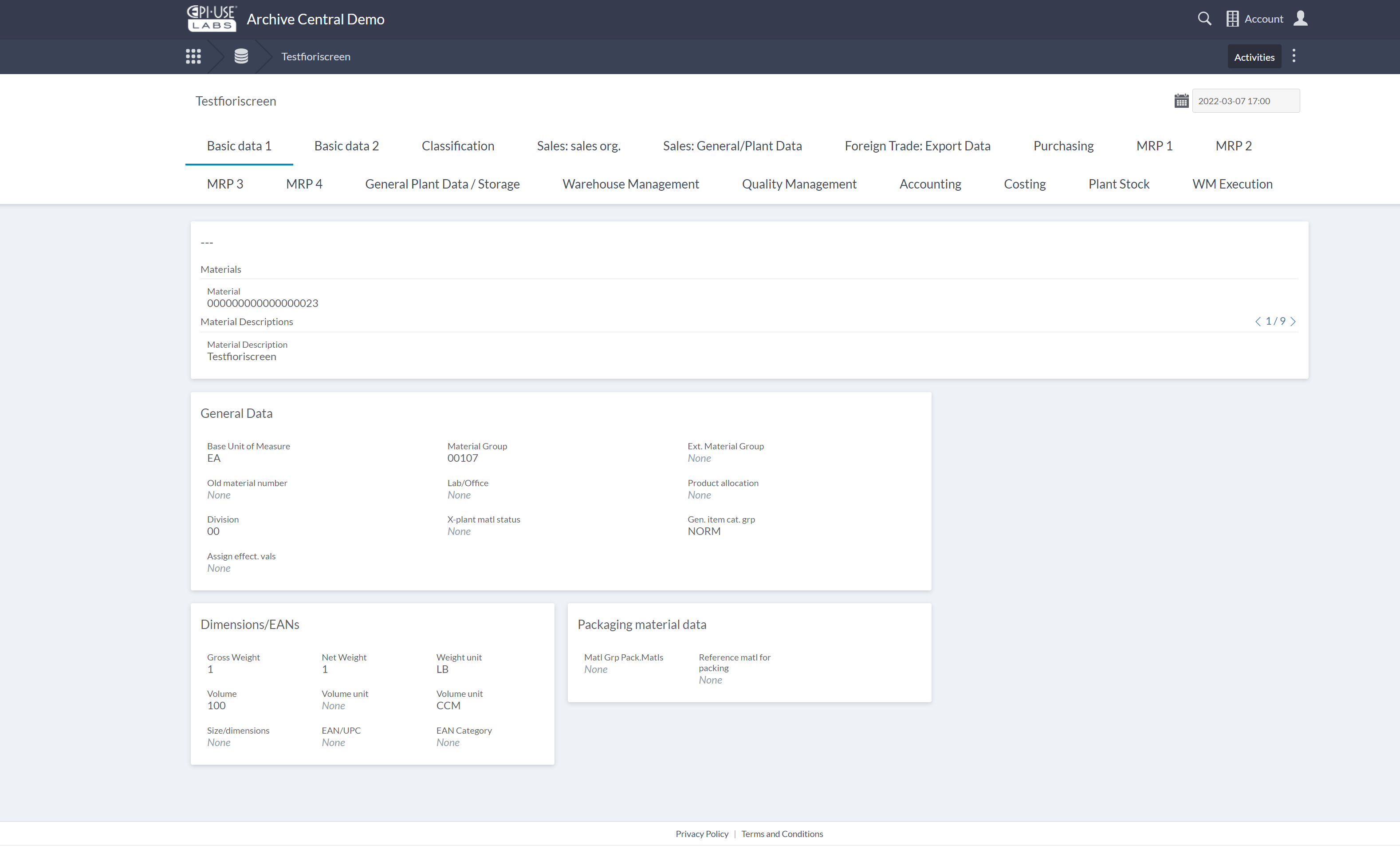
Die zugrundeliegende Technologieplattform selbst ist eigentlich nicht völlig neu. Als Unternehmen haben wir über 1.000 Kunden und waren mit dem, was für die Verwaltung unserer Interaktionen mit ihnen zur Verfügung stand, nicht mehr zufrieden. Wir wechselten vor vielen Jahren von einem Standardanbieter für Ticketing und Support zu unserer eigenen Plattform, Client Central. Nach der letzten Zählung hat sie 19.000 Benutzer, von denen im letzten Monat über 400 aktiv waren. Die Plattform Archive Central nutzt die gleiche Basis und profitiert von neuen Funktionen und Merkmalen, sobald diese verfügbar werden. Sie wird völlig separat in einer dedizierten Instanz pro Client bereitgestellt und profitiert von allen Sicherheitsvorkehrungen des Hyper-Scalers und unseren eigenen ergänzenden Vorkehrungen. Sowohl Client Central als auch Archive Central werden jährlichen Penetrationstests durch akkreditierte externe Organisationen unterzogen.
Archive Central unterstützt die Stilllegung von nicht-SAP-Legacy-Systemen, aber sein wirklicher Wert liegt im SAP-Bereich. Es wurde speziell für die Verwaltung des komplexen und ausführlichen SAP-Datenmodells in Zusammenarbeit mit Spezialisten entwickelt. Auszüge aus SAP können automatisch eingelesen und in Sammlungen umgewandelt werden, wobei automatische Verarbeitungsentscheidungen getroffen werden (z. B. werden nur Felder mit Daten für mindestens einen Schlüssel angezeigt - zusätzliche Metadaten sind im Hintergrund und auf Knopfdruck sichtbar).
Die Metadaten aus SAP sind bereits in der Sammlung und sogar in den Verknüpfungen zwischen Sammlungen für verwandte Objekte enthalten (wie im bereits erwähnten Beispiel mit Kundenauftrag und Material). Jeder, der über die entsprechenden rollenbasierten Berechtigungen verfügt, kann das Layout ohne technische Kenntnisse oder Fähigkeiten ändern. Unstrukturierte Daten können aufgenommen und mit den strukturierten Daten verknüpft werden, um eine einfache Anzeige zu ermöglichen, und es gibt SAP-basierte Dienstprogramme zum Extrahieren der gängigsten Typen.
Wie unterstützen wir bei einer Stilllegung?
Unsere Teams übernehmen die Verantwortung für den gesamten SAP-Stilllegungsprozess: eine Analyse des SAP-Systems, um die verwendeten Daten zu verstehen; Workshops zur Abstimmung und Fertigstellung des Blueprints; Extraktion und Ingestion; und Anpassungen des Layouts nach dem User Acceptance Testing.