

Si vous n'avez pas encore eu à travailler avec des systèmes SAP "à visualisation uniquement" ou des données qui devraient vraiment être retirées, vous le ferez bientôt. Avec le renforcement des lois sur la protection des données dans le monde entier, juste avant la plus grande période de transformation massive de l'écosystème SAP de son histoire, il y aura des données et des systèmes hérités qui devront être retirés de manière rentable de toutes les organisations utilisant SAP.
"Archivage" par table ou par Objet Métiers
Dans les blogs précédents, j'ai évoqué la complexité du modèle de données SAP®. Il existe des interrelations très profondes entre différentes tables, parfois par le biais d'un lien intuitif (par exemple, un numéro d'adresse apparaissant dans les tables de Partenaires Commerciaux, Clients ou Fournisseurs). Cependant, dans certains cas, un utilisateur SAP ne remarquera jamais que le lien passe par un numéro interne.
Lorsqu'on parle de "démantèlement", le terme "archivage" revient souvent. Le mécanisme d'archivage traditionnel de SAP consiste simplement à télécharger les données de la base de données vers une archive physique. Ainsi, lorsque quelqu'un appelle un code de transaction pour visualiser ces données, la couche applicative ABAP sait qu'au lieu de diriger sa requête vers la base de données, elle doit interroger les fichiers pertinents pour lire les informations.
Mais les fichiers ne sont pas organisés par groupes logiques de données commerciales, ce n'est pas ce dont la couche applicative ABAP a besoin. Vous voulez simplement ouvrir le fichier et rechercher la clé XYZ au lieu d'effectuer une sélection SQL sur une table de base de données pour la clé XYZ.
Le temps de réponse sera normalement beaucoup plus lent et, bien entendu, les données archivées ne pourront pas être modifiées, mais le mécanisme reste le même. En matière de déclassement, les fichiers d'archives ne sont pas plus utiles que le téléchargement du contenu individuel des tables de la base de données, alors comment ces tables vont-elles être assemblées ? La logique de gestion nécessaire ne se trouve pas dans les archives ; elle était encore dans le système SAP et ne sera plus disponible.
Profiter des avantages de l'extracteur de Data Sync Manager
Pour conserver la possibilité de voir "l'instance" de l’Objet Métiers, nous ne voulons pas de fichiers pour une table avec plusieurs clés d'entreprise, mais plutôt des fichiers avec toutes les lignes de la table pour une clé spécifique ou un ensemble de clés. De plus, nous avons besoin d'une définition des métadonnées qui nous indique non seulement comment combiner les différentes lignes du tableau pour montrer l'instance de l'Objet Métiers, mais aussi comment cet Objet Métiers peut être relié ou lié à d'autres objets.
Par exemple, lors de la consultation d'une Commande client, il existe une clé pour le matériel référencé dans le poste, ce qui permet de combiner les données pour afficher une description du matériel (faisant partie de l'objet du matériel) lors de la consultation de la commande client elle-même. C'est là que l'extracteur SAP de Data Sync Manager™ entre en jeu : les données sont sélectionnées par clé et exportées avec tout le contenu pertinent des tables et une définition des métadonnées. La propriété intellectuelle exploitée a été créée et affinée au cours des deux dernières décennies dans plus de 700 installations SAP, dans le monde entier et dans de nombreux secteurs d'activité ; elle a été utilisée pour créer de nouveaux systèmes SAP, fusionner des données dans des systèmes et, surtout, fournir ou anonymiser des données de test.
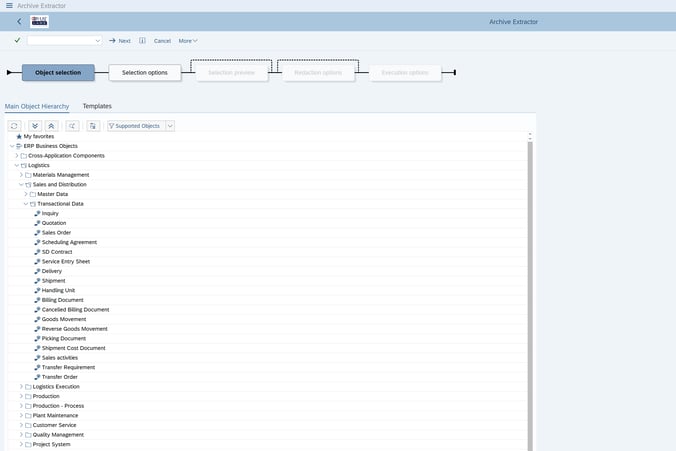
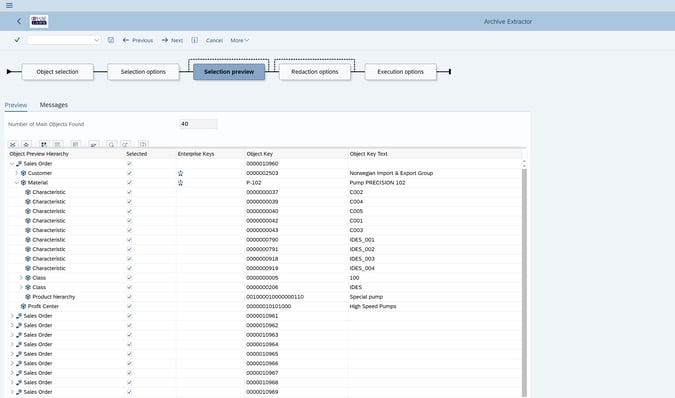
L'extraction comprend également une partie des informations de l'étiquette pour les champs ayant des valeurs spécifiques au domaine. L'utilisateur voudra voir la description, et non le code arbitraire qui est stocké dans le champ lui-même. Dans certains cas, les codes peuvent obtenir leur description à partir d'une table de configuration connexe, et peuvent même dépendre des niveaux de configuration. Par exemple, la description d'une rubrique peut différer selon l'endroit de l'entreprise où travaille le salarié. Bien entendu, il existe également des versions linguistiques de ces descriptions stockées dans la table de configuration.
Du côté de l'extraction, cela semble facile, alors où est le problème ?
Jusqu'à présent, nous avons examiné les tables de base de données simples et transparents, mais il existe également des tables plus complexes, comme les tables de cluster. En bref, vous pouvez considérer la table cluster comme une ligne d'un tableau normal, mais avec un ou plusieurs champs qui sont des enregistrements de données spéciales compressées, comme un fichier zip. Pour interpréter les données compressées, vous devez connaître le format du cluster, qui peut être différent selon les rangées. Par exemple, les tables réelles au sein du cluster pour les données de paie varient entre les différentes versions nationales ; il existe des utilisations plus simples des clusters pour la performance ou l'économie d'espace.
Le cluster RFBLG est utilisé depuis longtemps dans de nombreuses versions de SAP pour gérer quelques documents des comptables. Dans ce cas, la clé de la table se trouve dans la partie transparente, mais tant que les données ne sont pas "déballées" du cluster, nous ne savons pas dans quelle table se trouvent réellement les données. Il existe plusieurs variantes et toute solution qui tente de déclasser SAP devra en aborder plusieurs.
Données non structurées dans vos systèmes SAP
Les données que nous avons analysées jusqu'à présent sont ce que l'on appelle des données "structurées" : le même modèle de métadonnées répété à l'infini avec les mêmes rangées de tableaux liés pour encapsuler les données. Ensuite, nous devons considérer les données non structurées qui ont été générées ou introduites dans vos systèmes SAP. Il existe plusieurs façons de stocker des documents dans SAP, mais la plus courante consiste à utiliser un serveur de contenu. Le principe de base est le suivant : le Système de Gestion de Base de Données Relationnelle sous-jacent à votre application SAP n'était pas particulièrement adapté au stockage de documents Word, PDF, etc. SAP a donc introduit Archive Link, qui permet aux organisations de déplacer ce contenu vers une base de données distincte ou un emplacement de système de fichiers. Cela permettait de stocker les données plus efficacement, puis de transmettre les informations en temps réel au serveur d'application SAP et à l'interface graphique (GUI) lorsqu'un utilisateur demandait à voir le document. Il sera nécessaire de formuler un plan pour télécharger en masse ces documents et les rendre disponibles lorsque SAP sera déclassé. Ce problème peut être résolu par le cryptage au niveau de la couche SAP ou, à défaut, par l'utilisation de la RPA ou de la technologie des "bots".
Les données non structurées peuvent également être stockées directement dans la base de données SAP, via la capacité de Generic Object Services (GOS). Il s'agit d'un petit bouton qui peut apparaître en haut à gauche de nombreuses transactions pour indiquer que GOS est disponible. L'utilisateur peut y rédiger des notes publiques ou privées ou l'utiliser pour télécharger un document Word ou PDF.
Des données invisibles ?
Et puis, il y a les données qui ne sont pas vraiment là… en tout cas, pas toujours. Il existe des types de données assez volumineux générés à partir de données structurées, introduits dans un template ou un formulaire et stockés temporairement avant d'être envoyés. Il peut s'agir de bulletins de salaire, de notifications de paiement, de factures générées et de nombreux autres types de documents. Il s'agit d'un mélange difficile de données structurées et d’aménagements non structurées, combiné pour donner un aménagement très identifiable. La plupart des gens pensent qu'il s'agit d'un document PDF qui se trouve quelque part dans SAP ou dans un serveur de contenu, mais ce n'est pas le cas. Les fiches de paie et tout ce qui utilise SAP Forms sont les principaux domaines à prendre en compte.
OK, on l'a. Maintenant, où est-ce qu'on l'emmène ?
Au cours des cinq prochaines années, un nombre sans précédent de systèmes SAP seront déclassés. Pendant ce temps, le passage au cloud (en 2018, Cisco a prévu qu'à l'heure actuelle, 95 % du trafic total des centres de données serait du trafic cloud) et au SaaS devrait se poursuivre sans relâche. Ainsi, lorsque nous avons décidé de créer une solution pour traiter les anciens systèmes et les anciennes données, nous avons voulu utiliser une technologie moderne qui s'adapterait à l'évolution de nos clients, et non à leur origine. Archive Central est consommé comme une application SaaS et avec elle, vous n'aurez jamais d'autres factures ni de coûts imprévus. Nous pouvons nous adapter aux restrictions ou préférences géographiques et le choix de l'hypercalculateur est flexible (je ne vous dirai pas quels sont nos préférés, car ils ont tous des départements juridiques qui décuplent notre organisation).
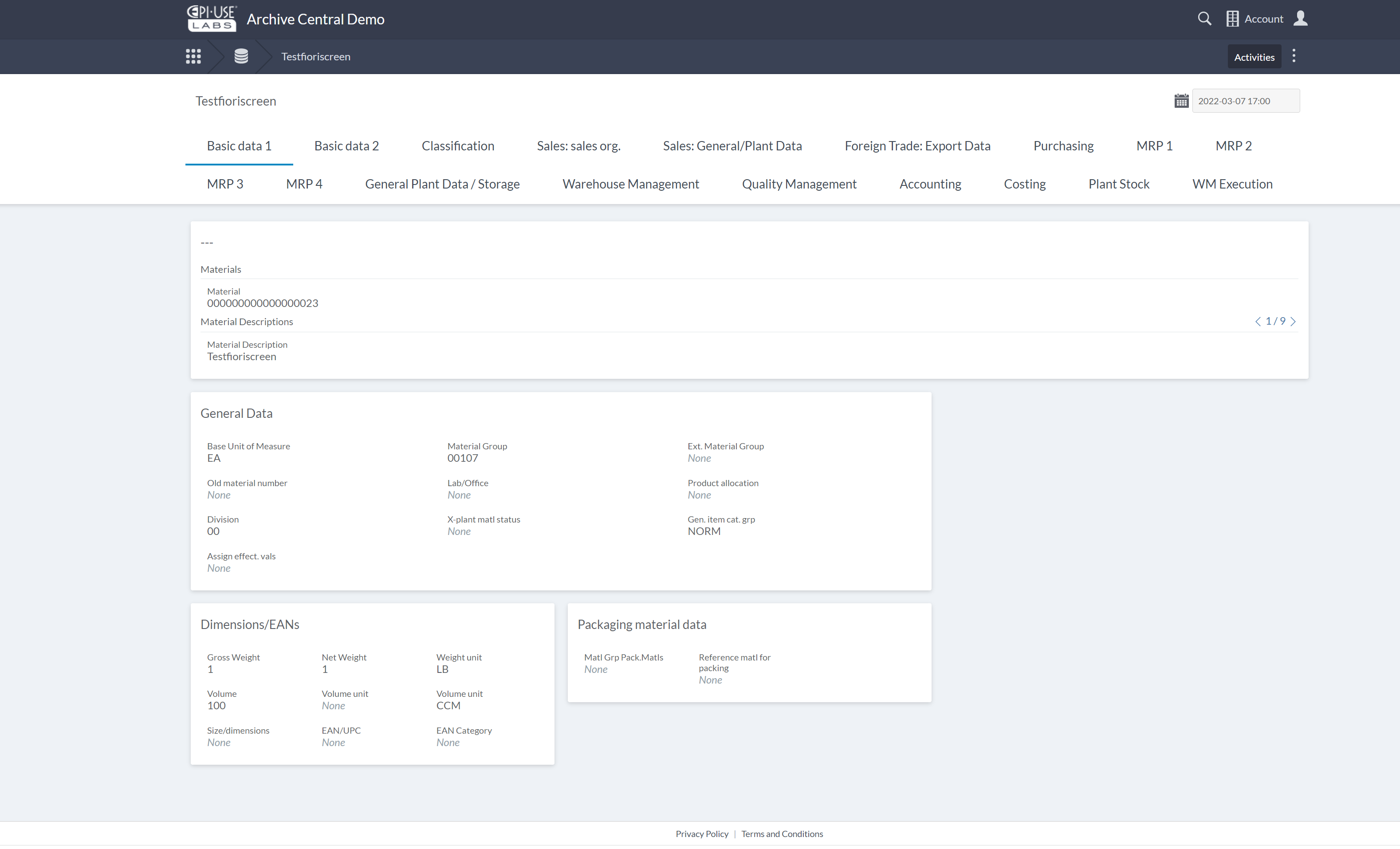
La plateforme technologique sous-jacente n'est en fait pas totalement nouvelle. En tant qu'organisation, nous avons plus de 1.000 clients et nous étions désillusionnés par ce qui était disponible pour gérer nos interactions avec eux. Il y a plusieurs années, nous sommes passés d'un fournisseur de tickets et d'assistance à notre propre plateforme, Client Central : au dernier recensement, elle compte 19.000 utilisateurs et plus de 400 utilisateurs actifs au cours du dernier mois. La plateforme Archive Central partage la base et bénéficie des nouvelles fonctions et caractéristiques au fur et à mesure de leur disponibilité. Elle est déployée de manière totalement indépendante sur une instance client dédiée, bénéficiant de toutes les protections de sécurité d'hypercalculateur et de ses add-ons. Client Central et Archive Central sont tous deux soumis à des projets annuels de tests de pénétration menés par des organisations externes accréditées.
Archive Central prend en charge le démantèlement des anciens systèmes non-SAP, mais c'est dans l'espace SAP qu'il prend toute sa valeur. Il a été spécialement conçu pour gérer le modèle de données SAP, complexe et verbeux, avec l'aide de spécialistes. Les extraits de SAP peuvent être ingérés automatiquement et transformés en Collections avec des décisions de traitement automatisées (par exemple, n'afficher que les champs contenant des données pour au moins une clé - les métadonnées supplémentaires sont en arrière-plan et visibles d'un simple clic).
Les métadonnées de SAP sont déjà inhérentes à la collection et même aux liens entre les collections pour les objets liés (comme l'exemple de la Commande Client et le Matériel mentionné précédemment). Toute personne disposant d'autorisations basées sur les rôles peut modifier la mise en page sans aucune connaissance ou compétence technique. Il est possible d'ingérer des données non structurées et de les lier aux données structurées pour en faciliter l'affichage. Il existe des utilitaires basés sur SAP pour extraire les types de données les plus courants.
Comment pouvons-nous aider au démantèlement ?
Nos équipes prennent en charge l'ensemble du processus de déclassement de SAP : une analyse du système SAP pour comprendre les données utilisées, des ateliers pour convenir et finaliser le plan, l'extraction et l'ingestion, et les ajustements de la mise en page après les tests d'acceptation par les utilisateurs.
Leave a Comment: